Johann Elert Bode
Johann Elert Bode (1747 – 1826) was a German astronomer known for his reformulation and popularization of the Titius–Bode law. Bode determined the orbit of Uranus and suggested the planet's name.
He began his career with the publication of a short work on the solar eclipse of 5 August 1766. This was followed by an elementary treatise on astronomy entitled Anleitung zur Kenntniss des gestirnten Himmels (1768, 10th ed. 1844), the success of which led to his being invited to Berlin by Johann Heinrich Lambert in 1772 for the purpose of computing ephemerides on an improved plan. There he founded, in 1774, the well-known Astronomisches Jahrbuch, 51 yearly volumes of which he compiled and issued.
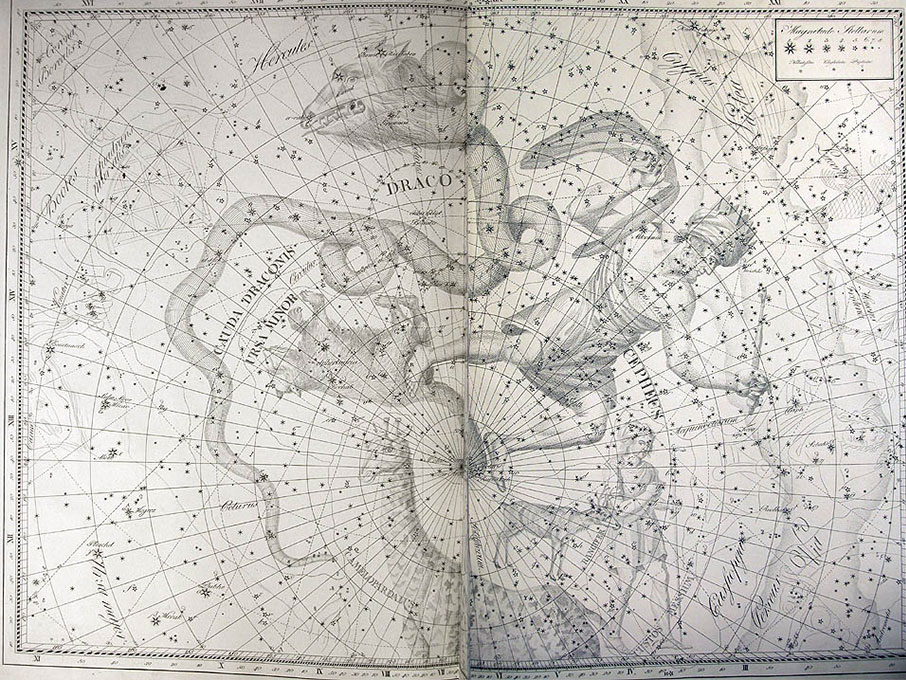
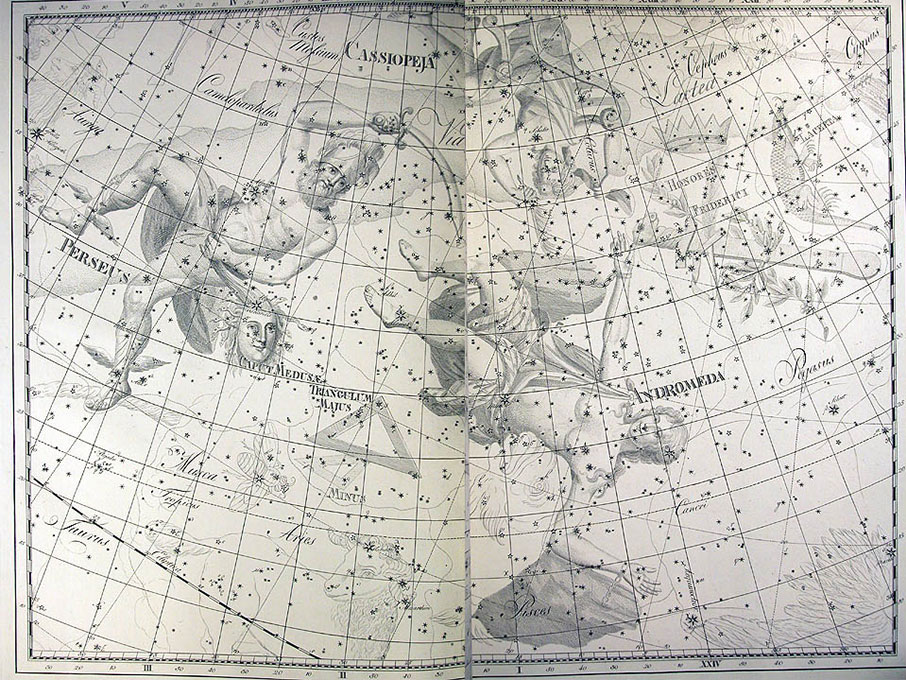
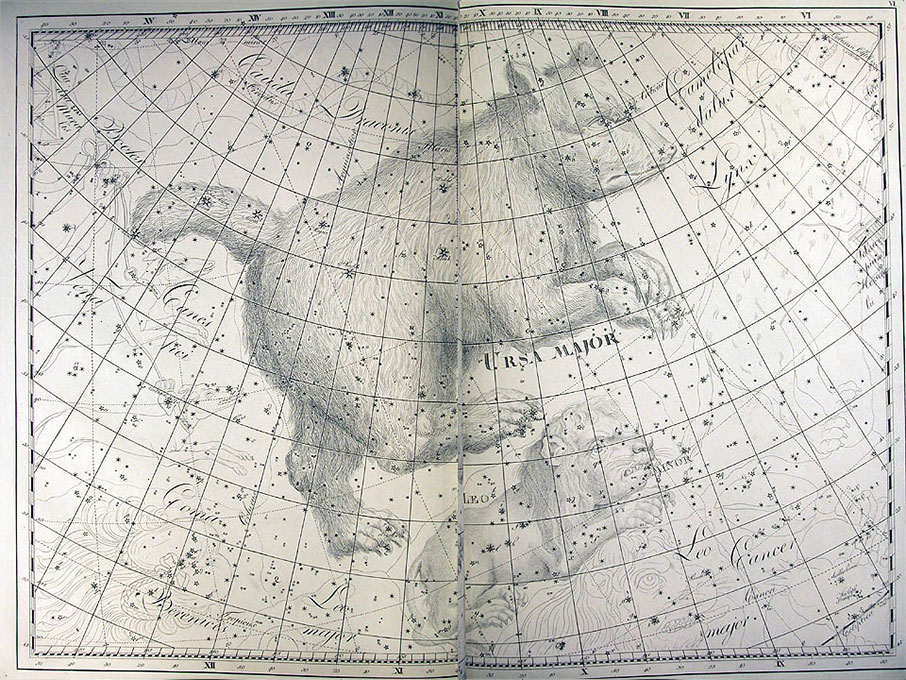
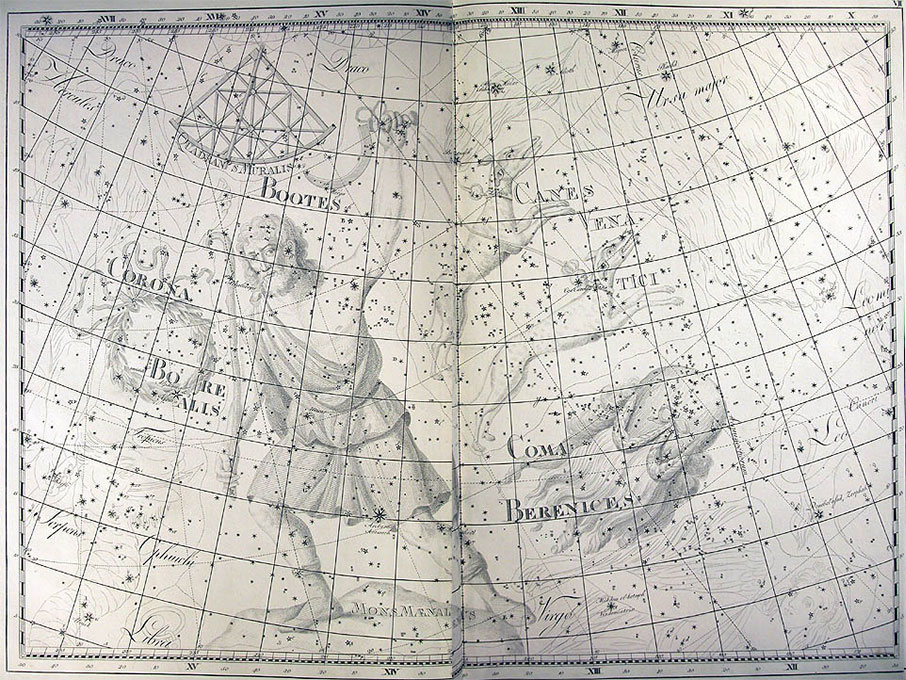
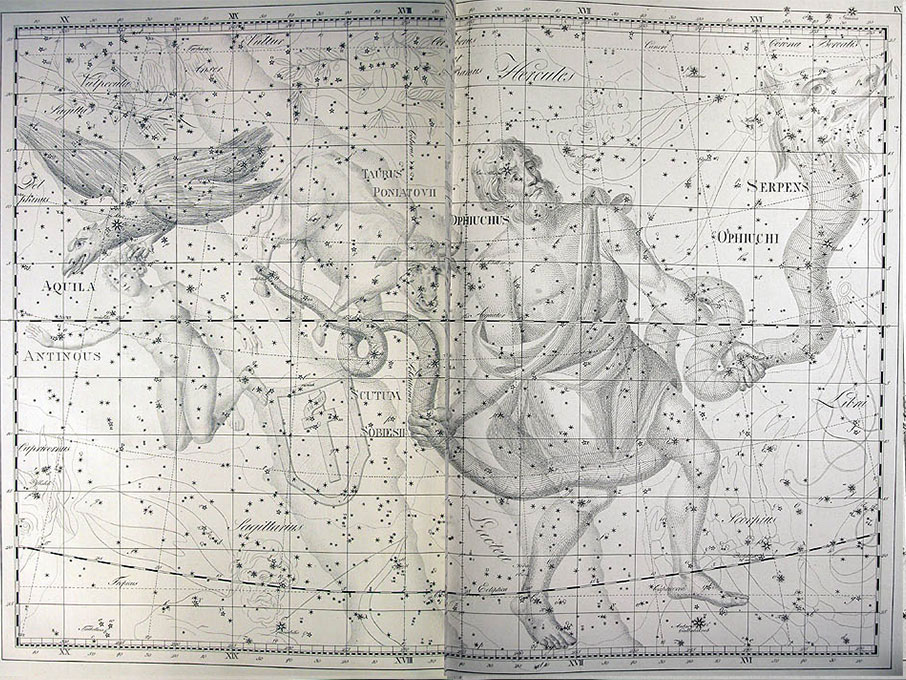
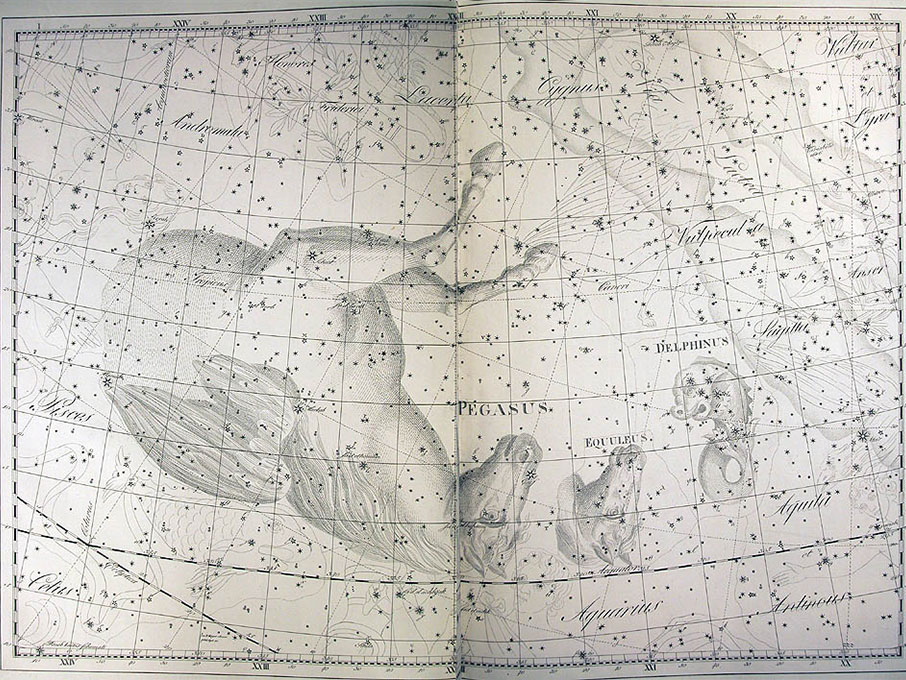
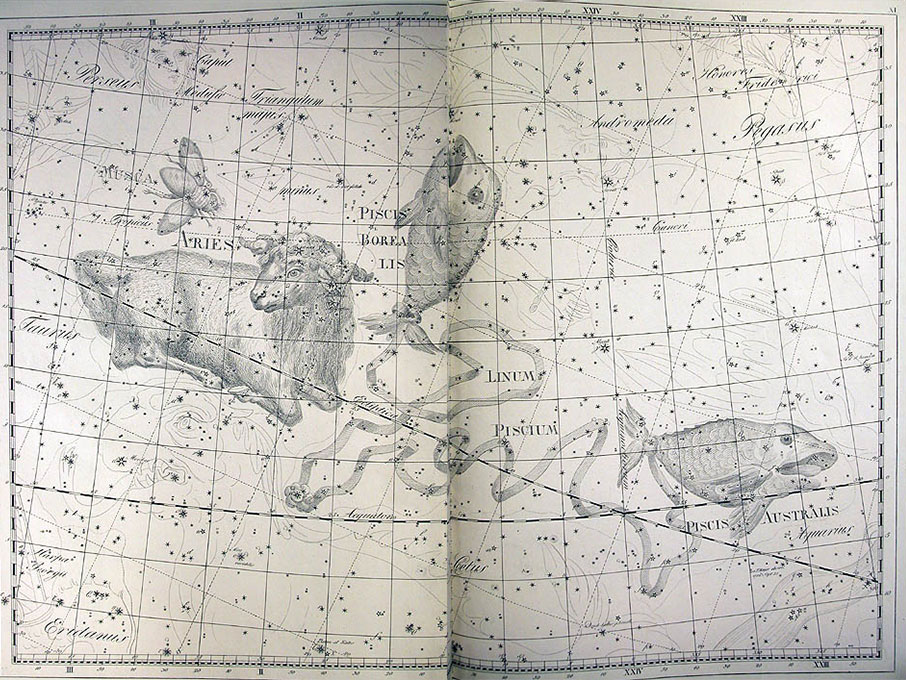
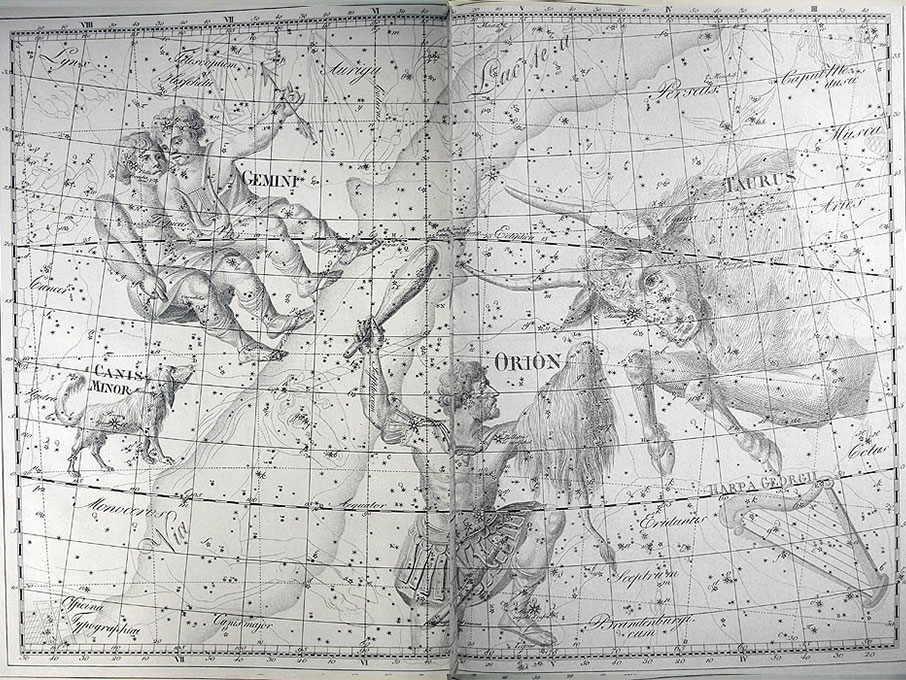
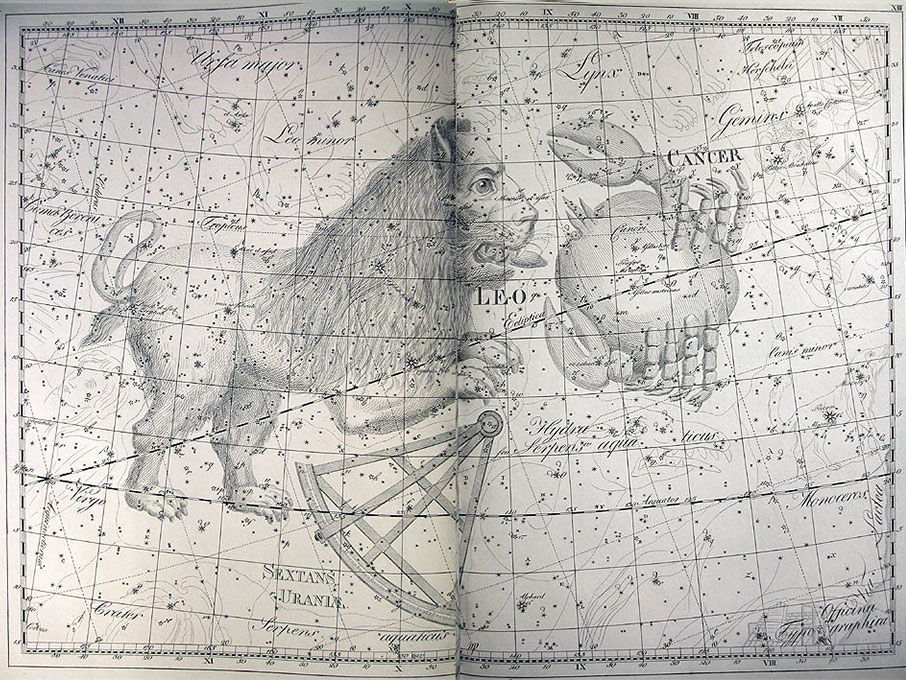
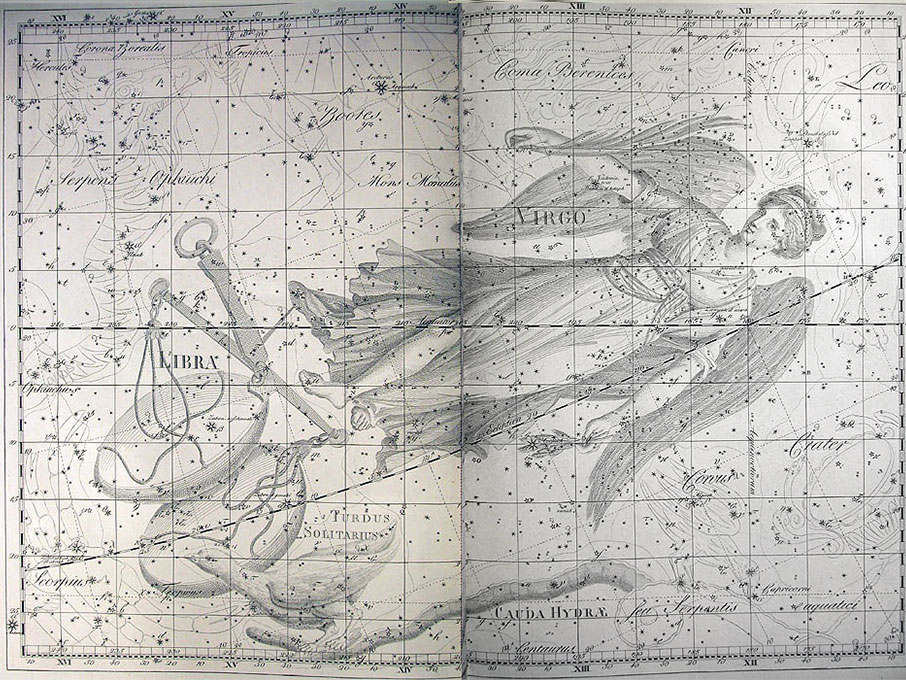
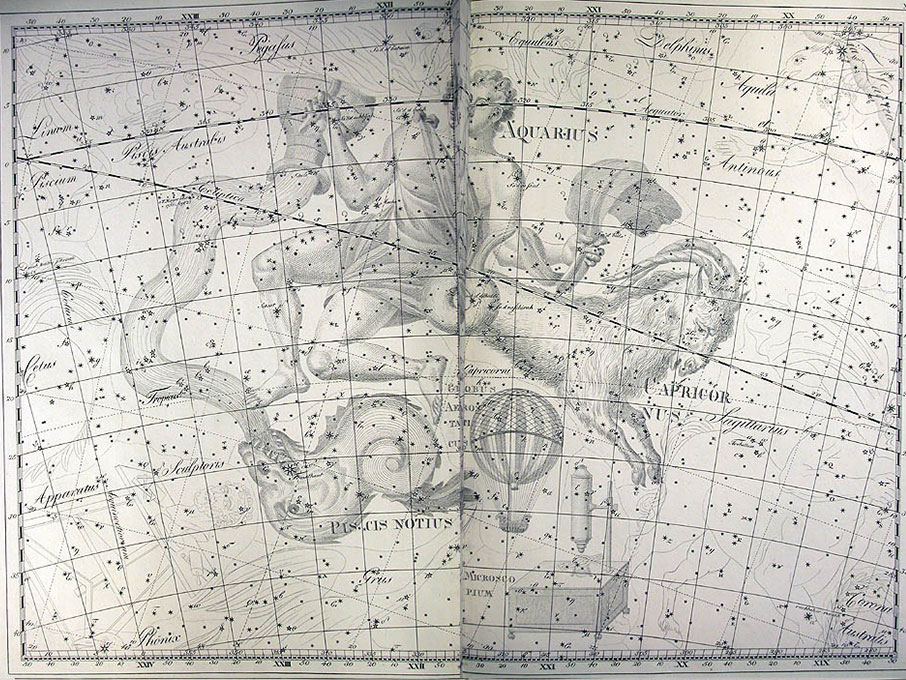
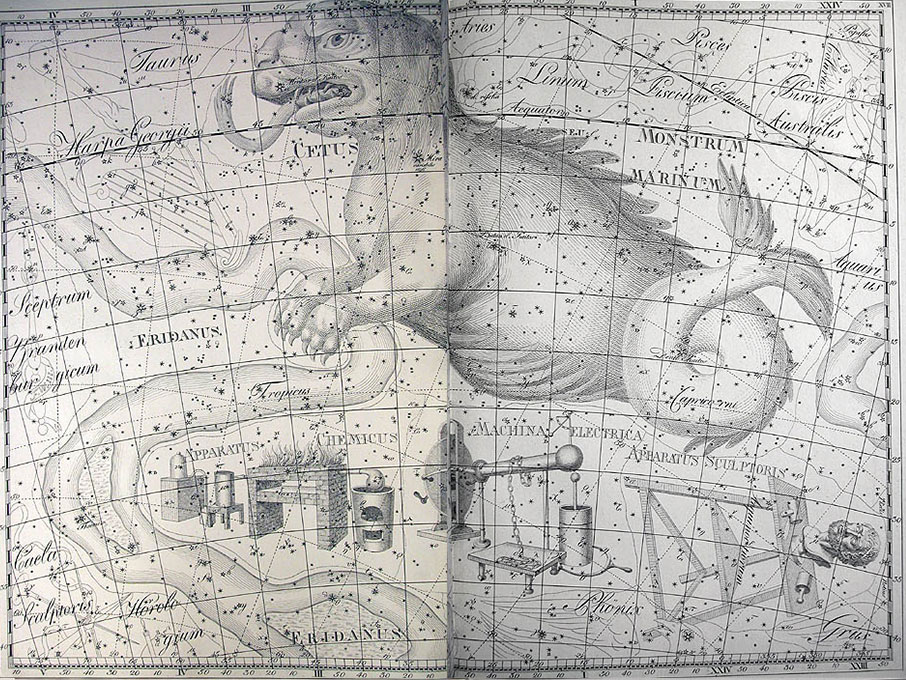
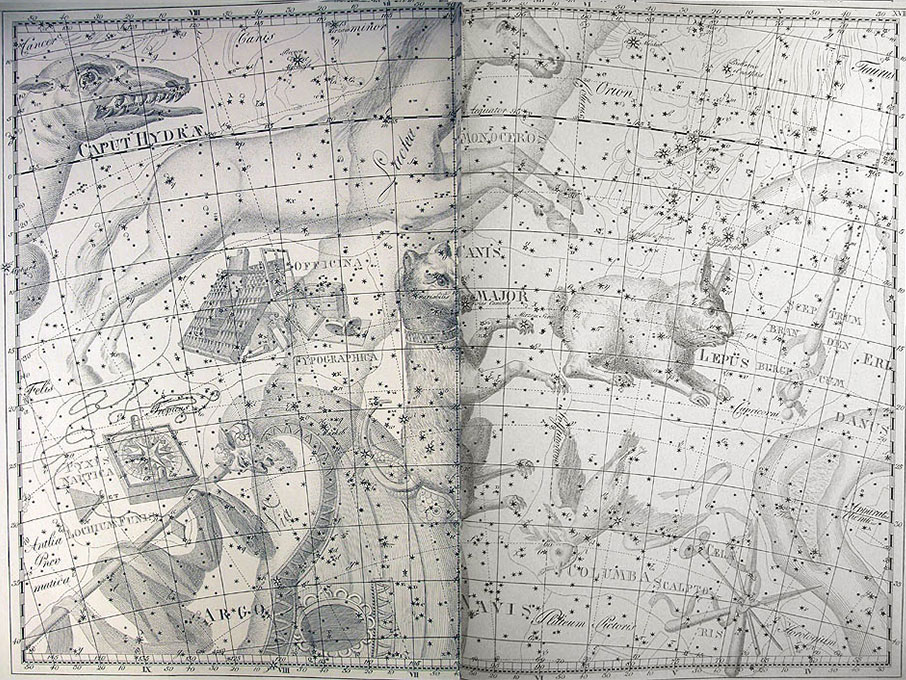
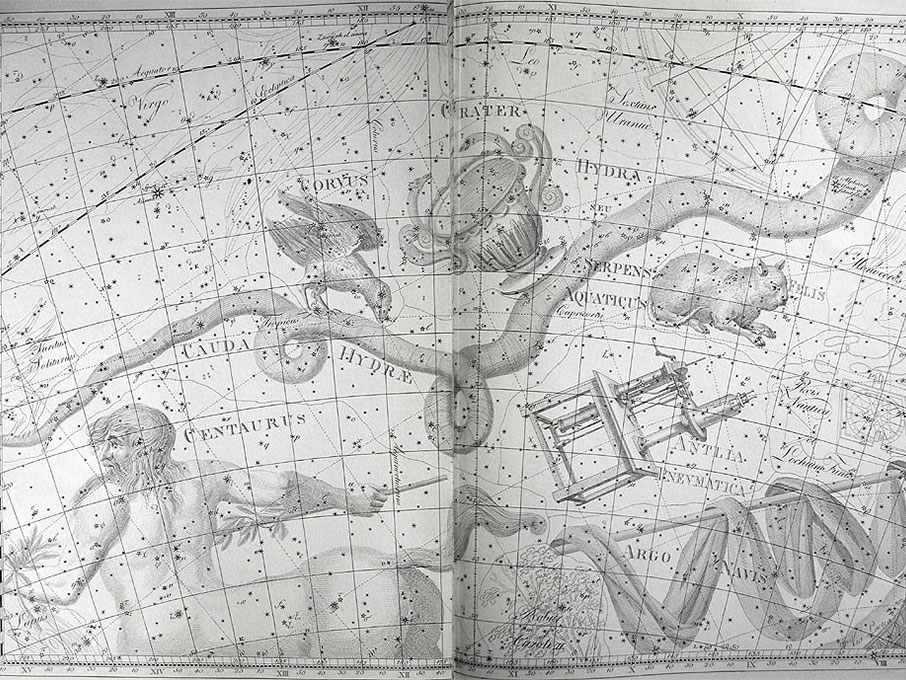
He became director of the Berlin Observatory in 1786, from which he retired in 1825. There he published the Uranographia in 1801, a celestial atlas that aimed both at scientific accuracy in showing the positions of stars and other astronomical objects, as well as the artistic interpretation of the stellar constellation figures. The Uranographia marks the climax of an epoch of artistic representation of the constellations. Later atlases showed fewer and fewer elaborate figures until they were no longer printed on such tables.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bode also published another small star atlas, intended for astronomical amateurs (Vorstellung der Gestirne). He is credited with the discovery of Bode's Galaxy (M81). Comet Bode (C/1779 A1) is named after him; its orbit was calculated by Erik Prosperin. Asteroid 998 Bodea, discovered 1923 August 6 by Karl Reinmuth at Heidelberg, was also christened in his honour, the letter 'a' added to its name to fulfil the convention that asteroids were given feminine names.
His name became attached the 'law' discovered by Johann Daniel Titius in 1766. Bode first makes mention of it in the Anleitung zur Kenntniss des gestirnten Himmels in a footnote, and although it is often officially called the Titius–Bode law, it is also commonly just called Bode's law. This law attempts to explain the distances of the planets from the Sun in a formula although ironically it breaks down for the planet Neptune which was later discovered in Berlin. It was the discovery of Uranus at a position predicted by the law which aroused great interest in it. There was actually a gap (with no planet) between Mars and Jupiter, and Bode urged a search for a planet in this region which culminated in a group formed for this purpose, the so-called "Celestial Police". However before the group initiated a search, they were trumped by the discovery of the asteroid Ceres by Giuseppe Piazzi from Palermo in 1801, at Bode's predicted position.
Latterly, the law fell out of favor when it was realised that Ceres was only one of a small number of asteroids and when Neptune was found not to be in a position required by the law. The discovery of planets around other stars has brought the law back into discussion.
Bode himself was directly involved in research leading from the discovery of a planet - that of Uranus in 1781. Although Uranus was the first planet to be discovered by telescope, it is just about visible with the naked eye. Bode consulted older star charts and found numerous examples of the planet's position being given while being mistaken for a star, for example John Flamsteed, Astronomer Royal in Britain, had listed it in his catalog of 1690 as a star with the name 34 Tauri. These earlier sightings allowed an exact calculation of the orbit of the new planet.
Bode was also responsible for giving the new planet its name. The discoverer William Herschel proposed to name it after George III which was not accepted so readily in other countries. Bode opted for Uranus, with the apparent logic that just as Saturn was the father of Jupiter, the new planet should be named after the father of Saturn. There were further alternatives proposed, but ultimately Bode's suggestion became the most widely used - however it had to wait until 1850 before gaining official acceptance in Britain when the Nautical Almanac Office switched from using the name Georgium Sidus to Uranus. In 1789, Bode's Royal Academy colleague Martin Klaproth was inspired by Bode's name for the planet to name his newly discovered element "uranium".
Wikipedia